Cursus est le périodique électronique étudiant de l'École de bibliothéconomie et des sciences de l'information (EBSI) de l'Université de Montréal. Ce nouveau périodique diffuse des textes produits dans le cadre des cours de l'EBSI.
ISSN 1201-7302
cursus@ere.umontreal.ca URL: http://www.fas.umontreal.ca/ebsi/cursus/En cette seconde et derničre année de sa maîtrise, M. Plourde est inscrit dans le profil de recherche. Ses intéręts de recherche portent, d'une part, sur les documents structurés et, d'autre part, sur la diffusion et le repérage de l'information dans Internet. Il a un baccalauréat en mathématiques. Il a également suivi des cours en informatique (gestion et intelligence artificielle) et en histoire de l'art.
Son expérience de travail se situe principalement dans le domaine de l'informatique comme analyste. Depuis son retour aux études, il donne des cours en micro-informatique ŕ temps partiel. Auparavant, il a travaillé deux années en France ŕ titre de consultant en base de données dans le milieu bancaire. Il a commencé sa carričre en informatique ŕ la Société Radio-Canada oů il a occupé différentes fonctions pendant une dizaine d'années et oeuvré principalement dans les systčmes d'information.
Critčre et évaluation d'outils de recherche des ressources dans Internet a été écrit ŕ l'automne 1995 dans le cadre du cours Structures et fonctions des logiciels documentaires (BLT 6351)donné par le professeur Yves Marcoux.
Tout texte demeure la propriété de son auteur. La reproduction de ce texte est permise pour utilisation individuelle. Tout usage commercial nécessite une permission écrite de l'auteur.
Il est d'ores et déjŕ reconnu que le repérage d'information dans Internet constitue une tâche difficile. Plusieurs outils, spécialisés dans le repérage d'information, tels Lycos ou Yahoo, ont été développés afin de répondre ŕ ce besoin pressant. Est- ce que tous ces sites offrent les męmes services? Vous l'avez deviné, bien sűr, la réponse est non: chacun possčde ses particularités.
Dans la premičre partie de cette étude, nous établissons des critčres d'évaluation qui nous permettrons de mieux comprendre les forces, les faiblesses, les similitudes et les différences entre ces outils de recherche et d'orienter le choix d'un outil d e recherche. Nous suggérons que ce choix soit fonction, d'une part, des services offerts et, d'autre part, des besoins de l'utilisateur. Cette premičre partie se divise en quatre sections: la premičre aborde la typologie des outils de recherche, la seco nde porte sur les services de mise ŕ jour, la troisičme traite des services de repérage et la derničre étudie les services de présentation des résultats.
Dans la seconde partie, nous évaluons treize outils de recherche en nous basant sur les critčres suggérés.
Fondamentalement, les critčres d'évaluation d'outils de recherche sont similaires ŕ ceux utilisés lors de l'évaluation d'un ouvrage de référence électronique. Ces critčres sont: l'objectif du site, la crédibilité de l'organisation responsable, la cou verture, l'objectivité, l'auditoire visé, l'organisation, la fréquence de mise ŕ jour, le coűt, l'originalité, le format de présentation, la convivialité, l'historique des recherches, les menus d'aide, l'utilisation d'opérateurs booléens, la troncature, e tc. Nous ne passerons pas en revue l'ensemble de ces critčres mais nous nous attarderons spécifiquement ŕ ceux qui sont liés aux services de mise ŕ jour, de repérage et de présentation des résultats que nous expliciterons plus loin.
Avant de passer au vif du sujet, il est nécessaire d'apporter quelques précisions. Dans la littérature, les sites spécialisés en repérage d'information sont désignés sous plusieurs dénominations. Parmi celles-ci on retrouve: robots (robots, webcr awlers), service de repérage (search service) et moteurs de recherche (search engines). De notre point de vue, cette terminologie porte ŕ confusion. En effet, les robots constituent un service en amont dont le but est de recueilli r les données afin de mettre ŕ jour une base de données W3. Le service de repérage est, quant ŕ lui, un service en aval qui correspond naturellement ŕ l'interface utilisateur pour effectuer la recherche. Enfin, les moteurs de recherche offrent des servi ces pour tirer profit des données et établir le pont entre la base de données W3 et l'interface utilisateur.
Dans cette étude, nous utiliserons l'expression «outils de recherche» telle que définie dans le Vocabulaire d'Internet préparé par Marcel Bergeron et Corinne Kempa, terminologues ŕ la Direction des services linguistiques de l'Office de la langue française: programme qui indexe le contenu de différentes ressources d'Internet, et plus particuličrement de sites W3, qui permet ŕ l'internaute de rechercher de l'information ŕ partir d'un navigateur W3, selon différents paramčtres, en se servant de mot s clés, et qui permet d'avoir accčs ŕ l'information ainsi trouvée.
De plus, dans le cadre de cette étude, nous ferons une distinction sémantique entre "site Web" et "base de données W3". Un "site Web" sera un site qui diffuse de l'information dite primaire (telles les pages d'accueil personnelles) et une "base de don nées W3" sera un site qui diffuse de l'information dite secondaire (tels Lycos ou Yahoo).
Vous trouverez une bibliographie ŕ la fin de ce travail. Celle-ci est également disponible en ligne ŕ l'URL suivant:
http://tornade.ere.umontreal.ca/~plourdej/moteurs.html
Nous y avons noté les références. De plus, ŕ cet URL, d'autres références sur l'évaluation d'outils de recherche sont disponibles.
Cette étude a eu lieu pendant les mois de septembre ŕ décembre 1995. Une mise en garde s'impose: compte tenu de l'évolution rapide des outils de recherche, il est fort probable que les fonctionnalités offertes par ces outils auront évolué et que certa ines de nos remarques ne s'appliqueront plus dans les mois ŕ venir.
Un outil de recherche se compose d'une partie technique et d'une partie fonctionnelle. La partie technique touche plus spécifiquement les éléments suivants: le type de serveur (PC, Mac, Sun), le systčme d'exploitation (UNIX, Microsoft Windows), le nomb re de serveurs (sites miroirs), le type de base de données (fichiers plats, bases de données relationnelles ou orientées objets), le langage de programmation (C++, Pascal), le langage d'interprétation (Perl, Tcl), le moteur de recherche (WAIS, GLIMPSE, PU RSUIT, etc.) et sűrement d'autres éléments. Bien que trčs intéressante, cette composante ne fera pas l'objet de notre étude.
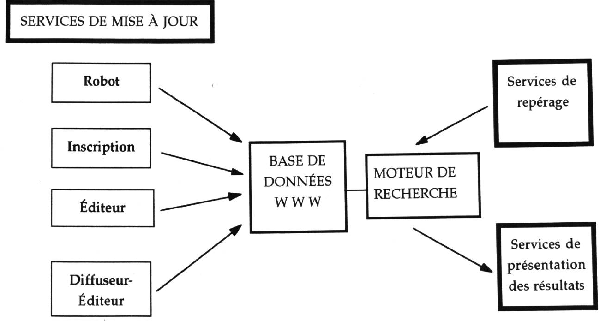
La partie fonctionnelle porte plus spécifiquement sur les services associés ŕ l'exploitation d'une base de données W3. Nous porterons une attention particuličre aux services de mise ŕ jour des données, ŕ ceux de repérage et ŕ ceux de présentation des
résultats. Les services de mise ŕ jour ont pour mission de colliger les données du Web afin de constituer une base de données W3. Les services de repérage ont, quant ŕ eux, la mission d'offrir une interface utilisateur doublée d'un moteur de recherche
pour l'exploitation de ces données. Finalement, les services de présentation des résultats correspondent tout simplement aux fonctions offertes pour l'exploitation des données repęchées. La figure suivante illustre ces différents services.
Les outils de recherche peuvent ętre classifiés selon plusieurs types. Pour n'en citer que quelques-uns, il y a ceux qui produisent des index (Lycos), des répertoires (Yahoo), des métarépertoires (URL Square, métarépertoire au Japon) et des métaindex (All-in-One). Dans le cadre de cette étude, nous nous limiterons aux outils de recherche de type index et répertoire.
Tel que son nom l'indique, ce type est associé ŕ tous les outils de recherche dont les fonctions de repérage reposent principalement sur l'utilisation d'index. Nous y retrouvons, entre autres, des sites tels: ALIWEB, CUI World Wide Web Catalog, InfoSe ek, Lycos, Open Text Web Index, Web Crawler, WWW Home Pages Harvest Broker et WWW Worm.
Un des avantages de ce type réside dans le fait que l'utilisateur n'a pas ŕ connaître la catégorie (et la structure hiérarchique) dans laquelle pourrait exister l'information recherchée. L'information n'est pas compartimentée en catégories. La recher che s'opčre principalement par concordance avec un modčle (pattern matching). Cette approche peut entraîner de bons taux de rappel mais aussi beaucoup de bruit, c'est-ŕ-dire une baisse du taux de précision. Fondamentalement, ce type se rapproch e de celui utilisé pour la recherche par sujet dans les OPACs traditionnels. Cependant, contrairement ŕ ces derniers, il n'y a pas de vocabulaire contrôlé. Notons également que, généralement, le type index est basé sur des techniques automatisées pour rép ertorier l'information produite dans le Web.
Ce type est associé ŕ tous les outils de recherche dont les fonctions de repérage reposent principalement sur une classification afin d'organiser l'information selon une propriété (thématique, chronologique, etc.). En général, c'est la classification de type thématique qui est privilégiée. Dans ce type, nous retrouvons, entre autres, les sites tels: Einet Galaxy, GNN's Whole Internet Catalog, The World-Wide Web Virtual Library, Yahoo, The Clearinghouse for Subject-Oriented Internet Resource Guides [U n. de Mich.].
Lorsque l'utilisateur connaît le domaine de sa recherche et la structure hiérarchique liée ŕ un outil de recherche, le type répertoire peut s'avérer trčs intéressant. En catégorisant l'information, il est facile de butiner d'un document ŕ l'autre port ant sur un męme sujet. Cette approche permet de réduire le taux de bruit mais aussi d'augmenter le taux du silence (en supposant qu'un document est classifié dans une seule catégorie). Fondamentalement, ce type est analogue au plan de classification q ue l'on retrouve dans les bibliothčques traditionnelles (mais en beaucoup moins élaboré). Notons également que, généralement, le type répertoire est basé sur des techniques manuelles pour répertorier l'information produite dans le Web. En général, il y a une valeur ajoutée. Bien que certains de ces outils offrent la recherche ŕ l'aide d'index, celle-ci est beaucoup plus limitée que dans les outils de type index.
La pierre d'assise de tout systčme d'information est sans contredit la base de données sur laquelle repose celui-ci. Les éléments utilisés pour constituer les bases de données W3 varient énormément d'un outil de recherche ŕ l'autre. Nous allons exami ner les services de mise ŕ jour selon les critčres suivants: le mode opératoire de mise ŕ jour des données diffusées dans le Web, les types d'objets répertoriés, l'information retenue des objets répertoriés, la taille et la fréquence de mise ŕ jour de la base.
Les méthodes utilisées pour la mise ŕ jour de la base de données W3 sont principalement le robot, l'inscription, l'éditeur et le diffuseur-éditeur. Notons que ces méthodes ne sont pas mutuellement exclusives. Un outil de recherche peut utiliser l'une ou l'autre, ou toutes ces méthodes ŕ la fois. Par exemple, la base de données Yahoo utilise les méthodes de robot, de l'inscription et de l'éditeur.
Le robot est sans aucun doute l'une des méthodes les plus répandues pour l'exploration du Web. Les sites tels Infoseek, Lycos, Open Text Web Index, WebCrawler, Whole Internet Catalog, Harvest Broker, WWW Worm et Yahoo utilisent cette méthode. Parfois, dans la littérature, on emploie des noms encore plus évocateurs tels spiders (araignée), worms (ver de terre, se faufiler) ou Web Wanderer (vagabond du Web). Malgré l'exotisme des images évoquées par ces noms, la réalité est toute simple: un robot (spiders, worms ou Web wanderer ) est tout simplement un programme qui s'exécute sur un ordinateur relié au Net et qui explore systématiquement celui-ci de maničre ŕ colliger l'information présente. C'e st l'automatisation et la systématisation de ce que l'on fait de chez soi en se baladant dans le Web (et pourtant on est bien assis devant son ordinateur...).
Avec le mécanisme du robot, le diffuseur d'information (vous et moi) joue un rôle complčtement passif car le robot se charge de rechercher l'information diffusée. Celui-ci ne demande pas son reste (ni votre permission) et visite lien par lien la toile du Web selon un algorithme de recherche. Cet algorithme suit généralement un de ces deux principes: par la nature hiérarchique des liens dans une page Web, l'exploration faite par les robots suit une recherche en profondeur (l'algorithme est basé sur l 'exploration récursive du premier lien hypertextuel rencontré) ou en largeur (l'algorithme repose sur l'exploration de tous les noeuds d'une page avant de descendre dans un des liens hypertextuels). Pour obtenir plus d'information sur les robots, sur les techniques utilisées et sur les controverses ŕ leur sujet, je vous invite ŕ consulter les excellents articles de Martijn Koster (voir bibliographie).
Une derničre remarque: la tâche des robots, soit d'explorer le Web dans sa totalité, constitue un problčme de taille et, dans les faits, pratiquement impossible ŕ résoudre. C'est un peu comme si vous vouliez parcourir tous les chemins de la plančte, d e la maničre la plus efficace, en un temps minimal.
Plusieurs outils de recherche offrent aux utilisateurs d'inscrire leurs publications. Parmi celles-ci, nous retrouvons InfoSeek, Lycos, Open Text, WebCrawler, Harvest Broker, WWW Worm et Yahoo. Notons toutefois que le rôle du diffuseur de l'informati on primaire est, en général, trčs minime et se limite ŕ donner uniquement une adresse URL. Par la suite, l'outil de recherche visitera (fort probablement ŕ l'aide d'un robot) l'URL indiqué pour en extraire l'information.
Vous avez produit un article sur le Web et désirez le faire connaître? Inscrivez-vous (ou plutôt inscrivez votre URL préféré) aux bases citées précédemment. Par ailleurs, pour exploiter efficacement ces bases de données en vue de vous publiciser, nous vous conseillons de lire la section suivante intitulée L'information retenue des objets répertoriés. En effet, l'information répertoriée et retenue varie énormément d'un outil de recherche ŕ l'autre.
La méthode de l'éditeur est utilisée uniquement dans les outils de recherche de type répertoire. Ces sites profitent de personnes qui se spécialisent dans un domaine précis et qui s'occupent d'en maintenir la cohésion.
Les sites Galaxy et Whole Internet Catalog font partie de cette catégorie. Les diffuseurs sont également encouragés ŕ proposer des sujets. Ceux-ci seront inclus dans la base de données uniquement sous l'approbation d'un responsable du domaine (guest editors). Évidemment, contrairement aux techniques automatisées, cette technique est plus coűteuse en ressources humaines mais permet généralement une valeur ajoutée ŕ l'information répertoriée.
Bien que trčs peu utilisée, nous en faisons quand męme mention. Cette méthode, assez originale, est toute ŕ l'opposé de celle des robots vue précédemment. Le diffuseur d'information primaire joue un rôle beaucoup plus actif. En effet, l'outil de rech erche est tributaire du bon vouloir des diffuseurs d'information primaire. Ce sont eux qui décident des objets ŕ diffuser (c'est la revanche des écrivains sur les éditeurs).
Néanmoins, le diffuseur doit se conformer ŕ une norme pour décrire l'objet de sa diffusion. Le seul site qui utilise cette méthode, ŕ notre connaissance, est celui d'Aliweb. Pour tout objet de diffusion, le diffuseur prépare un fichier, selon des nor mes prescrites, puis le signale ŕ l'outil de recherche qui se chargera de récupérer la description contenue dans le fichier pour l'inclure dans sa base. De plus, l'un des services de l'outil de recherche visitera réguličrement le site Web pour prendre en compte toute modification éventuelle ŕ la description.
Cette méthode comporte plusieurs avantages. La plus importante concerne la description de l'objet ŕ diffuser. Contrairement aux robots qui ne font qu'extraire les données du Web, cette méthode permet une valeur ajoutée par le diffuseur. Celui-ci peu t, en effet, décrire l'objet diffusé, lui associer des mots clés et le classifier selon la norme émise. En contrepartie, actuellement, Aliweb comporte peu d'éléments (environ 6,000 documents).
Le type d'information retenue varie d'un outil de recherche ŕ un autre. Avant de pouvoir interroger une base de données, il faut nécessairement alimenter celle-ci. Plusieurs questions se posent et parmi celles-ci la plus importante consiste ŕ détermi ner les types d'objets ŕ répertorier (HTML, Gopher, Ftp, etc.). Cette question est fondamentale ŕ la définition des services de repérage qui seront offerts par la suite.
Par exemple, la base de données de LYCOS est constituée uniquement de documents de type HTML, GOPHER et FTP. Les fichiers de type Usenet (groupe de discussion) ou Telnet sont tout simplement ignorés par ses robots. Pour obtenir de l'information d'une page Web, l'outil est certes intéressant. Par contre, si vous cherchez de l'information produite dans un groupe de discussion, ŕ la fine pointe de l'actualité, nous vous recommandons InfoSeek ou The Whole Internet Catalog. En opposition ŕ Lycos qui ess ait d'indexer le Net, les responsables de Whole Internet Catalog s'emploient ŕ trouver les liens les plus prolifiques (hotlist) en consultant les groupes de discussion ou les listes What's New.
Un second exemple est la base de données InfoSeek. C'est une base ŕ but lucratif mais qui permet l'accčs gratuit ŕ un sous-ensemble des produits offerts. Cette base est, en fait, constituée de plusieurs bases de données. D'une part, elle offre des ré férences ŕ des pages Web et ŕ des messages récents de groupes de discussion. D'autre part, InfoSeek offre, contre rémunération, un accčs ŕ des données autres que celles du Net: plus de 80 périodiques informatiques, certaines agences de presse, la base de donnée Medline et plusieurs autres.
Un dernier exemple est la base de données de Clearinghouse for Subject-Oriented Internet Resource Guides. Cette base contient environ 400 guides spécialisés dans plusieurs sujets que l'on retrouve dans Internet. Ces guides sont écrits en format HTML ou en format texte. Ils peuvent contenir des références ŕ des documents de type W3, Gopher ou FTP mais celles-ci sont parfois décrites en texte sans lien hypertextuel.
A chaque objet répertorié correspond un enregistrement dans la base de données. Selon l'outil de recherche, la nature de l'enregistrement peut varier énormément. Minimalement, celui-ci contient l'adresse URL et le titre de l'objet répertorié. Il peu t également, par exemple, contenir les en-tętes, des mots clés ou, mieux encore, l'intégralité des pages Web. Évidemment, la qualité des services de repérage sera directement proportionnelle ŕ la richesse de cet enregistrement.
Par exemple, ŕ chaque document W3 répertorié par LYCOS correspond un enregistrement contenant le titre, une partie de l'en-tęte, les cent mots les plus significatifs, les vingt premičres lignes du texte, la taille en octets, la taille en nombre de mots et le nombre de liens. Morale de l'histoire, si vous voulez inscrire votre page W3 chez Lycos, prenez garde ŕ vos vingt premičres lignes!
La base de données de Open Text, qui contient l'intégralité de chaque page Web répertoriée, associe ŕ chaque document un extrait, un titre, le premier en-tęte, l'URL et les liens hypertextuels. C'est de loin le site qui exploite le mieux la structure logique des documents HTML. Par ailleurs, WebCrawler indexe tout le contenu des documents répertoriés mais n'exploite pas la structure logique de ceux-ci. Pis encore, CUI World Wide Web Catalog indexe uniquement les titres des documents répertoriés!
Bien qu'elle dépende directement de l'information retenue des objets répertoriés et du mode opératoire du repérage des données, la taille de la base de données est un critčre souvent utilisé dans les études comparatives d'outils de recherche. C'est pou rquoi nous avons décidé de l'inclure dans notre étude.
La taille des bases est, comme vous pouvez l'imaginer, trčs variable. D'ailleurs les différentes études sont parfois contradictoires ŕ cet effet. Les chiffres varient énormément selon la définition donnée aux documents d'une base de données (par exem ples, considčre-t-on un seul URL par page ou l'ensemble des URLs contenus dans une page, est-ce un document intégral ou uniquement son URL, etc.) et la date ŕ laquelle ont été prises les statistiques (l'évolution trčs rapide du Web rend vite ces chiffres obsolčtes). Par conséquent, nous devons utiliser ces chiffres avec précaution, ŕ titre indicatif uniquement et éviter toute conclusion hâtive.
Par exemple, la base de données GNN Whole Internet contient 2,000 liens en comparaison de 10,75 millions pour Lycos et pourtant le GNN's Whole Internet n'est pas moins bon que Lycos. Comme on a vu précédemment, GNN Whole Internet est un outil de recherche de type répertoire qui utilise la méthode éditeur alors que Lycos est un outil de recherche de type index qui utilise la méthode des robots. Tous deux ont des visées bien différentes. La premičre fonctionne manuellement, ce qui lui confčre une valeur ajoutée, alors que la seconde est entičrement automatisée. Si vous ętes intéressés aux sujets de derničre heure de l'Internet, il peut ętre intéressant de visiter GNN Whole Internet.
De męme, la base de données de Clearinghouse for Subject-Oriented Internet Resource Guides est constituée uniquement de 400 guides sur les ressources de l'Internet. Ceci n'enlčve rien ŕ la qualité et ŕ l'intéręt de celle-ci.
Ceci étant dit, il est quand męme intéressant de pouvoir comparer la taille des bases de męme nature. Dans les bases de type index, d'une part, nous avons Lycos avec 10,75 millions d'URL avec des références au document primaire et, d'autre part, nous retrouvons WWW Worm, Open Text et InfoSeek qui ont respectivement 3 millions, 1 million et 400,000 documents intégraux. Dans les bases de type répertoire, on retrouve Galaxy avec des index de 100,000 documents intégraux et Yahoo avec 66,000 références.
Les données du Net sont trčs volatiles: ŕ chaque jour s'ajoutent de nouveaux documents, d'autres sont modifés ou détruits (dead link). Particuličrement pour les outils de recherche qui utilisent les robots, il est important que ces bases soient consta mment remises ŕ jour. Par exemple, la base de données Lycos est entičrement reconstruite chaque semaine. Environ 10,000 documents s'y ajoutent hebdomadairement. Open Text suit la męme fréquence. WebCrawler, quant ŕ lui, remet ŕ jour sa base ŕ toutes l es six semaines.
Les bases de données Yahoo et Harvest Broker opčrent une reconstruction journaličre de leur base respective. Pour d'autres sites gérés manuellement, tels Whole Internet Catalog et WWW Virtual Library, la responsabilité incombe aux éditeurs (difficilem ent quantifiable).
A cause de la méthode diffuseur-éditeur utilisée par Aliweb, l'ajout de nouvelles références est laissé ŕ l'entičre responsabilité des diffuseurs d'information primaire. Similairement, la base de données Clearinghouse for Subject-Oriented Internet Res ource Guide est enrichie de nouveaux guides, préparés et maintenus par des étudiants en bibliothéconomie et science de l'information (SILS, University Library at University of Michigan), ŕ intervalle de 5 ŕ 8 mois.
L'interface utilisateur, plus ou moins complexe selon les sites, comporte l'entrée des requętes de recherche (termes recherchés et paramčtres de la recherche). Nous porterons notre attention uniquement sur les interfaces utilisant des formulaires HTML. Évidemment, en fonction des services offerts, l'interface utilisateur varie énormément entre les outils de recherche. De plus, il n'y a pas de normalisation et chaque outil possčde sa propre interface. Nous allons examiner les services liés ŕ la documen tation offerte en ligne et aux fonctions pour le repérage.
La documentation pour les services de repérage aide les utilisateurs ŕ atteindre deux objectifs. Le premier est d'évaluer la pertinence de la base, c'est-ŕ-dire sa nature (objets répertoriés), ses objectifs, son autorité, etc. Le second est la maîtri se et l'utilisation efficace des services de repérage et la vérification du comportement de ces services (obtient-on les résultats escomptés?).
Par exemple, l'outil de recherche Galaxy permet, ŕ l'aide de liens hypertextuels, de trouver de l'information ŕ propos de l'organisation responsable du site. De plus, une introduction complčte et détaillée avec des exemples de stratégie de recherche e t une page portant sur les nouvelles entrées (What's New) sont disponibles. De loin, il s'agit de l'un des meilleurs avec Harvest Broker et WWW Worm.
En contrepartie, nous retrouvons CUI World Wide Web Catalog qui n'offre aucun service d'aide. WebCrawler, quand ŕ lui, offre une documentation correcte mais sans plus. Notons toutefois, ŕ la défense de WebCrawler, que celui-ci offre peu de fonctions et que l'utilisation de son interface est trčs simple. En conclusion, plus les services de repérage sont sophistiqués, plus claire et précise doit ętre la documentation.
Nous avons vu, dans la section portant sur les services de mise ŕ jour, que les types d'objets et l'information retenue varient d'un outil de recherche ŕ l'autre. L'organisation structurelle des données a un impact direct sur les outils de repérage et sur la qualité des fonctions offertes. Restreindre l'indexation ŕ certains champs améliorera la précision de nos recherches. De męme, la notion de pertinence est trčs importante en recherche de l'information. C'est pourquoi plusieurs outils de recherc he utilisent le principe de pondération sur les mots recherchés.
De plus, une panoplie d'opérateurs sont utilisés pour raffiner le repérage. Nommons, entre autres, les opérateurs booléens, les opérateurs de voisinage et les opérateurs de chaînes de caractčres. Notons que ces opérateurs reposent essentiellement sur le principe de concordance de modčle (pattern matching). Par ailleurs, certaines bases offrent des langages de recherche qui permettent l'utilisation d'expressions réguličres.
Néanmoins, contrairement aux recherches automatisées dans les bases de données traditionnelles, plusieurs fonctions ne sont toujours pas offertes par les outils de recherche. Pour n'en citer que quelques-unes, prenons les opérateurs numériques et l'hi storique de recherche. Actuellement, il est impossible d'effectuer une requęte comportant une comparaison de dates. De męme, aucun outil ne permet d'établir une session usager de maničre ŕ conserver un historique des recherches. Il est ŕ noter qu'une te lle fonctionnalité pourrait théoriquement ętre assurée par l'amélioration de la gestion de l'historique de navigation dans les logiciels clients W3 pour les pages comportant des formulaires.
L'indexation du texte intégral constitue un moyen, critiquable certes pour le bruit résultant, qui peut s'avérer intéressant. Par ailleurs, l'indexation selon la structure logique d'un document est un moyen efficace pour cibler de l'information. Par exemples, le titre, les en-tętes, le résumé ou les premičres lignes d'un texte forment ŕ coup sűr des entités pour lesquelles les mots s'y rattachant ont une plus grande pertinence. Mais ce ne sont pas les seules. En plus de la structure logique du docu ment, il y a les noms d'URL et les noms de fichiers qui forment également des entités trčs pertinentes pour certains types de repérage.
Prenons l'exemple de Open Text Web Index qui offre quatre outils de repérage. Parmi ceux-ci, nous retrouvons le Power Search qui, selon plusieurs analystes, est l'interface la plus flexible du Web. Cette base contient les documents intégraux et la st ructure logique de ceux-ci, du moins en partie. Il est possible de faire des recherches sur le titre, le premier en-tęte, «_l'extrait_», les liens hypertextuels ou tout simplement le texte complet.
L'outil de recherche WWW Worm offre, quant ŕ lui, quatre champs indexés pour la recherche: le titre, le nom du fichier HTML, l'URL et les références ŕ un URL (références croisées). Ce dernier type de recherche permet de déterminer, par exemple, quels sont les documents de la base de données WWW Worm qui contiennent un lien hypertextuel ŕ votre page d'accueil. La recherche dans un URL offre la possibilité, par exemple, de rechercher des films en format MPEG (l'URL se termine par «.mgp») provenant de l a nasa (l'URL contient le mot «nasa» dans le nom de l'ordinateur hôte). Cet outil peut s'avérer trčs intéressant lorsqu'on connaît, du moins en partie, la nature de l'objet ŕ repęcher.
Une autre technique utilisée pour améliorer le repérage est d'associer un «_poids_» ŕ chacun des mots présents dans un document répertorié. Cette technique a plusieurs variantes. Un mot reçoit un poids plus ou moins grand selon le nombre de fois et/ou les positions oů il apparaît dans le document. Par exemple, un mot apparaissant dans le titre d'un document recevra un poids plus grand qu'un mot n'apparaissant que dans le corps du document. De męme, un mot apparaissant deux fois recevra un poids plus gr and qu'un mot n'apparaissant qu'une seule fois. Ces poids associés aux mots présents dans un document sont utilisés lors d'une recherche pour calculer la «_pertinence estimée_» du document par rapport ŕ la requęte formulée. D'autres facteurs peuvent parti ciper également au calcul, tels la proximité des termes recherchés dans le document et le fait qu'ils apparaissent dans le męme ordre que dans la requęte ou non. Une des méthodes les plus populaires pour calculer la pertinence estimée d'un document par ra pport ŕ une requęte est celle de type WAIS.
Quelle que soit la méthode utilisée, la pertinence estimée est représentée par une «_pondération_» numérique, qui s'exprime habituellement sous la forme d'un nombre compris entre 0 et 100, 100 représentant la plus grande pertinence estimée possible. Ai nsi, la pondération d'un document en réponse ŕ une requęte de recherche donne une certaine indication de sa pertinence probable par rapport ŕ cette requęte.
Prenons l'exemple de l'outil de recherche Lycos. Celui-ci classe les résultats, c'est-ŕ-dire les références aux documents repęchés, par ordre décroissant des pondérations calculés pour chaque document en fonction des termes recherchés (relevancy r anking of terms). En d'autres mots, ŕ chaque document de la base est calculé un poids (weight terms). Cette pondération est calculée ŕ partir du nombre d'occurrences des termes recherchés, de leur position dans le document (le titre, les p remičres lignes du texte, etc.) et de leur proximité (s'il y a lieu). C'est sans aucun doute l'outil qui exploite le mieux cette technique.
L'outil de recherche WebCrawler utilise aussi l'algorithme de pondération. Néanmoins, cet algorithme est moins bien développé que celui de Lycos car, malgré l'indexation intégrale du texte, cette base n'utilise pas la structure logique du document (en -tęte, citation, etc.). La pondération repose uniquement sur le nombre d'occurrences du terme recherché sans tenir compte de sa position dans le texte.
Tous et chacun connaissent l'importance, dans la recherche automatisée, des opérateurs booléens (AND, OR, NOT). Plusieurs outils de recherche offrent ce type de fonction. Cependant, peu d'entre eux permettent une utilisation rigoureuse de ces opérateu rs (nous qualifions ceux-ci de pseudo-booléens).
Les outils de recherche Open Text Web Index et Einet Galaxy, quant ŕ eux, permettent une utilisation des opérateurs booléens (AND, OR, NOT) de maničre précise.
L'outil de recherche Lycos permet de spécifier le nombre minimum de termes ŕ ętre présents dans les résultats sans pouvoir déterminer lesquels parmi la liste des termes fournis (c'est un pseudo ET/OU booléen). Il est également possible d'utiliser la n égation d'un terme mais cette négation n'est pas exclusive. En effet, les documents contenant le terme recevront tout simplement une pondération moins significative et apparaîtront plus loin dans la lise des résultats. Toutes les fonctions de repérage o ffertes par Lycos reposent sur le concept de pondération.
En contrepartie, la base de données CUI World Wide Web Catalog considčre uniquement un OU implicite entre les termes de recherche.
En recherche automatisée, nous utilisons souvent des opérateurs de voisinage telles l'adjacence et la proximité. Peu d'outils de recherche offrent ce type de service.
La base de données Open Text Web Index permet l'adjacence. Un point intéressant, bien que ne faisant pas partie des services offerts par Lycos, les concepts d'adjacence et de proximité sont quand męme pris en considération. En effet, la pondération c alculée repose, en partie, sur la distance entre les termes recherchés.
Les opérateurs de chaînes de caractčres correspondent le plus souvent ŕ ceux que l'on connaît dans les traitements de texte. Nous retrouvons principalement les caractčres génériques pour la troncature ou la concordance avec un masque (wild card), les sous-chaînes (searching substring) et les phrases (searching phrase). De plus, certains outils de recherche permettent la recherche sur des mots apparentés (approximative matches). La distinction entre les majuscules et les minuscules est également supportée par quelques outils.
Plusieurs outils de recherche permettent l'utilisation de la troncature. Nous retrouvons, entre autres, Lycos et Harvest Broker.
Certains outils de recherche offrent des langages pour raffiner nos recherches ou l'utilisation d'expressions réguličres. Pour n'en nommer que quelques-uns, citons le WWW Worm qui utilise le programme «egrep» d'Unix et la base de données CUI World Wi de Web Catalog qui demande une connaissance du language PERL ou encore Harvest Broker qui permet d'utiliser des expressions réguličres. Mais, comme tout langage, l'investissement en temps pour en faire l'apprentissage en décourage plus d'un!
Lŕ encore, la diversité rčgne. La présentation des résultats est aussi vitale que l'ensemble des services vus jusqu'ŕ maintenant. En effet, quels sont les avantages d'obtenir 1,000 documents si les résultats sont difficilement exploitables? Nous all ons examiner ces services selon la documentation offerte et les fonctions de présentations.
La documentation pour les services de présentation des résultats assiste l'utilisateur ŕ interpréter correctement les résultats. Par exemple, comme on a vu précédemment, plusieurs outils de recherche offrent un classement des résultats obtenus selon l eur pondération par rapport ŕ la requęte de recherche (cf. 3.2.2). Malheureusement peu d'entre eux expliquent le calcul de cette pondération.
Pour faciliter le compréhension des résultats, plusieurs techniques sont disponibles. Nous retrouvons principalement l'affichage de la requęte utilisée et des formats de présentation variables (abrégé, moyen ou complet). Minimalement, les résultats c ontiennent l'URL et le titre du document repęché. Cette approche minimaliste est utilisée par CUI World Wide Web Catalog. L'URL est, en général, un lien hypertextuel menant au document primaire. A ces caractéristiques, d'autres outils de recherche joig nent un extrait du texte avec les termes associés ŕ la recherche mis en évidence (mots en contexte), la pondération, la taille du document et, parfois, la possibilité de réutiliser des résultats obtenus pour effectuer une autre recherche (see similar page).
Dans Lycos, lors de sa requęte, l'utilisateur peut préciser un nombre maximum de résultats (pour limiter le temps d'attente) et un seuil minimum de pondération (pour diminuer le bruit). De plus, il peut sélectionner un des trois types de format de pré sentation des résultats.
L'interface de sortie de WebCrawler est trčs simple. Il est possible de spécifier le nombre maximum de résultats (10, 25 ou 100). Les résultats sont ordonnés par ordre décroissant de pondération et contiennent uniquement le titre et la pondération. Ce peu d'information rend difficile l'évaluation des résultats.
L'outil de recherche Open Text Web Index permet en sortie de sélectionner une option pour faire apparaître dans leur contexte les termes de recherche. Un extrait accompagne les documents repęchés. Une option intéressante permet de rechercher des docu ments similaires ŕ celui qui est sélectionné (Find Similar Pages). L'algorithme est simple et repose sur le nombre d'occurrences de mots présents dans le document.
Harvest Broker offre la possibilité de sélectionner certains éléments, telles la pondération et la description, pour qu'ils apparaissent dans les résultats.
Plusieurs des évaluations d'outils de recherche publiées ont été produites, du moins en partie, en fonction des résultats obtenus ŕ des tests de performance (benchmark). La nôtre diffčre de celles-ci dans la mesure oů nous portons notre atten tion principalement sur les critčres que nous avons présentés précédemment. Nous avons évacué délibérément les notions de rappel et de précision des résultats pour nous attarder uniquement aux services offerts par un outil de recherche.
Cette évaluation n'a aucune prétention scientifique. Elle est divisée en deux sections selon le type index ou répertoire et porte sur treize outils de recherche. Tel que mentionné dans la premičre partie de ce travail, le type index est associé ŕ tous les outils de recherche dont les fonctions de repérage reposent principalement sur l'utilisation d'index. Le type répertoire est, quant ŕ lui, associé ŕ tous les outils de recherche dont les fonctions de repérage se basent principalement sur un plan de classification.
A chaque outil de recherche est associé une évaluation globale: soit (*) pauvre, (**) passable, (***) bon et (****) trčs bon. Si l'information concernant un critčre d'évaluation n'est pas disponible pour un outil de recherche, nous inscrivons un point d'interrogation, «_?_», ŕ sa description. Il peut arriver également que l'on ajoute, ŕ ce point d'interrogation, de l'information entre parenthčses dans le cas oů l'information n'a pu ętre vérifiée.
Tel que mentionné en introduction, il est fort probable que les fonctionnalités offertes par les outils de recherche auront évolué depuis la fin de nos travaux et que certaines de nos remarques ne s'appliquent plus.
L'originalité d'ALIWEB découle de son mode opératoire pour la mise ŕ jour de l'information diffusée dans le Web, c'est-ŕ-dire la méthode du diffuseur-éditeur. Le diffuseur d'information primaire est mis ŕ contribution dans l'élaboration des éléments s ervant au repérage. Il doit remplir un gabarit (template-type), selon le type d'objet ŕ diffuser, qui permet, entre autres, d'ajouter une description, des mots clés, une date de mise-ŕ-jour, des adresses électroniques.
Le repérage peut s'effectuer selon le type d'objet diffusé et les zones indexées tels le titre, la description, les mots clés et l'URL. En outre, il est possible de restreindre la recherche ŕ un domaine. Par exemple, on peut effectuer une recherche u niquement sur les documents produits au Canada (ca). Par ailleurs, la recherche peut porter sur une sous-chaîne, un mot complet ou une expression réguličre.
Pour les résultats en sortie, l'utilisateur peut spécifier, en plus du titre et de la pondération, les zones telles la description, les mots clés et l'URL. De plus, l'utilisateur a mainmise sur le nombre de résultats maximum désiré.
Bref, un outil dont nous pensons beaucoup de bien. Par contre, nous avons quelques réserves. En premier lieu, la documentation est plutôt déficiente sur la constitution du gabarit et sur l'utilisation d'expressions réguličres. De plus, la pondératio n sur les résultats en sortie n'est expliquée nulle part. Finalement, cette base contient peu de références (environ 6,000). Malgré tout, nous croyons que cette méthode comporte plusieurs avantages. Cet outil mérite un détour et nous lui attribuons tro is étoiles (***).
L'un des outils de recherche qui nous apparaît comme étant le plus décevant. Aucune documentation ou aide en ligne n'est disponible. On y indique que l'on peut utiliser les expressions réguličres en langage PERL sans aucune explication. Les document s sont ajoutés ŕ partir de listes What's New ou Hot List provenant de divers serveurs.
La présentation des résultats est correcte mais lŕ encore sans explication sur le contenu. Une description et une date de mise ŕ jour accompagnent ces résultats. Le seul point positif est la possibilité de refaire une recherche ŕ partir du formulaire contenant les résultats.
En résumé, nous ne pouvons pas dire que cet outil nous a enchanté. Nous lui accordons seulement une étoile (*).
Harvest est utilisé par plusieurs sites de recherche (appelés broker). Nous en parlerons de maničre générique. Cet outil s'appuie, pour le repérage d'information diffusée, sur les méthodes du robot, de l'inscription et de l'éditeur. Il est un de ceu x qui possčdent la documentation la plus complčte. Celle-ci comprend męme des explications sur les expressions réguličres.
Selon l'implantation, Harvest Broker fonctionne avec GLIMPSE ou WAIS comme moteur de recherche. GLIMPSE est de loin le moteur le plus évolué. En effet, il permet l'utilisation d'un sous-ensemble d'expression réguličre (dont la troncature), d'un opéra teur d'adjacence, d'opérateurs booléens, de mots apparentés et plus encore. Aussi, il est possible de restreindre notre recherche ŕ des zones tel l'auteur, le titre, l'URL, les mots clés ainsi que plusieurs autres selon le type d'implantation.
En sortie, nous obtenons l'URL, le titre et la taille du document. L'utilisateur peut indiquer le nombre de résultats maximum et sélectionner l'affichage de la pondération, de l'URL, de la description (si elle existe) et des références croisées lors d e sa requęte.
Un de nos outils préférés. Un exemple ŕ suivre pour tous ceux qui désirent développer un outil de recherche. Nous lui accordons le maximum, c'est-ŕ-dire quatre étoiles (****).
InfoSeek est ŕ but lucratif. Heureusement, un accčs gratuit est disponible ŕ une partie des données. C'est un des outils de recherche les mieux appréciés dans plusieurs études comparatives (la qualité se paie).
Bien qu'étant de type index, InfoSeek offre également une classification. On peut considérer cette base comme un hybride index-répertoire. La recherche s'opčre sur les noms de fichiers et leur contenu. Il est également possible de consulter une douz aine de sujets (topics). L'utilisateur peut spécifier le type d'objet désiré soit des pages Web, des groupes de discussion ou des FAQ d'Internet. La documentation est excellente.
Plusieurs fonctions sont disponibles pour le repérage. L'utilisation de guillemets permet de spécifier des phrases pour la recherche. De plus, InfoSeek porte une attention aux noms propres (les mots en majuscule) de maničre ŕ les distinguer des noms communs. Des opérateurs de voisinage, tels l'adjacence et la proximité, sont également offerts. Par contre, il n'y a pas d'opérateurs booléens mais néanmoins l'utilisateur peut spécifier des mots obligatoires (+) ou en proscrire (-).
En sortie, nous obtenons, en plus du titre, la pondération, la taille et le type du document, une description, des références croisées et le tout par ordre décroissant de pondération. Une particularité intéressante d'InfoSeek est la fonction Find simi lar pages qui, tel que son nom l'indique, permet de rechercher d'autres ressources similaires ŕ un résultat obtenu.
Un produit de grande qualité qui, comme Harvest Broker, vaut le déplacement. Nous lui attribuons quatre étoiles (****).
Type d'objet (utilisation d'une icône pour indiquer s'il s'agit d'une page W3 ou d'un titre Gopher, etc.), titre, pondération, URL, taille, description.
C'est probablement l'outil de recherche le plus populaire du Web. C'est ŕ tout le moins celui qui est le plus fréquemment cité dans les études comparatives. Tout comme InfoSeek, cet outil est ŕ but lucratif. Par contre, son utilisation est gratuite et ses revenus proviennent de sources publicitaires.
Lycos est constitué de deux bases: une petite d'environ 500,000 URL - oů chaque URL possčde une description - et une grande d'environ 10,75 millions d'URL (qui contient également les éléments de la petite base). Les objets répertoriés sont de type Gop her, FTP et page Web. La documentation est complčte. En outre, cette documentation décrit les différences majeures entre Lycos et ses principaux concurrents Yahoo et InfoSeek.
Les fonctions de recherche permettent des opérateurs pseudo-booléens (ALL/ANY en spécifiant un nombre de termes) ainsi que la négation. Le moteur de recherche s'appelle PURSUIT. Tout élément de la base est pondéré selon la position de celui-ci dans l es textes. Par exemple, un mot situé dans le titre ou dans le premier paragraphe d'une page aura un plus grand poids. Il est possible aussi de spécifier le degré de précision des termes recherchés (loose, fair, good, close, strong match). Nous devons a dmettre cependant que nous n'avons pas saisi toute la subtilité entre ces paramčtres!
En sortie, on peut préciser le nombre maximum de résultats et trois formats d'affichage. La présentation est trčs bien faite. A chaque paramčtre de recherche est associé le nombre de documents trouvés. De plus, pour chacun des résultats avec le form at complet, il y a l'URL, le titre, les 200 premiers caractčres dans les zones de type en-tęte, les 100 mots les plus significatifs, les 20 premičres lignes ou 20% du document (le plus petit des deux) et d'autres informations. On retrouve également la po ndération, le nombre de termes trouvés, le degré d'adjacence et parfois un extrait. Un point fort intéressant: tous les paramčtres de recherche sont mis en surbrillance dans l'extrait ce qui facilite l'évaluation des résultats retournés.
Cet outil est incontournable pour le repérage d'information dans le Web. Il constitue probablement celui dont les résultats de sortie sont les mieux présentés. Nous lui accordons le maximum, quatre étoiles (****).
C'est probablement l'outil de recherche qui exploite le mieux, avec Harvest Broker, la structure logique des documents. Cette base contient l'intégralité des pages répertoriées. La documentation est trčs bien faite.Plusieurs fonctions de recherche son t disponibles. L'utilisateur peut spécifier une zone tels le titre, la premičre en-tęte, l'URL ou l'extrait pour le repérage ou tout simplement explorer le texte intégral. De plus, sont présents les opérateurs booléens, l'opérateur de négation, l'adjace nce et la proximité.
Bien que n'offrant qu'un format en sortie, Open Text présente les résultats adéquatement. Ceux-ci comprennent, en plus du titre, la pondération, la taille et une description. De plus, ŕ chacun des résultats, l'utilisateur peut demander la recherche d e pages similaires tout comme Harvest Broker. Il est également possible d'obtenir les lignes du document primaire dans lesquelles apparaissent les mots recherchés. C'est le seul outil qui, ŕ notre connaissance, offre cette derničre fonctionnalité.
Cet outil de recherche nous apparaît trčs intéressant. Pour ceux qui se préoccupent de l'exploitation de la structure logique des documents, nous le leur conseillons vivement. Nous lui accordons quatre étoiles (****).
Cet outil de recherche est également trčs populaire dans le Web. La documentation est correcte, les fonctions de recherche sont limitées (opérateurs pseudo-booléens) et la présentation des résultats est plus que succincte (bien que l'on puisse spécifi er le nombre maximum de résultats). Malgré tout, ce site doit sa popularité ŕ sa simplicité. Un outil ŕ employer par les néophytes et les réfractaires d'opérateurs de recherche.
Nous lui accordons une étoile (*) .
Cet outil de recherche sert principalement ŕ répertorier des citations. La base de données contient l'intégralité des pages Web répertoriées. La documentation est bien faite et comprend des exemples de stratégies de recherche.
Une des particularités de cet outil est d'offrir la possibilité d'obtenir des références croisées. En plus du texte intégral, la base contient des index sur les URL, les liens hypertextuels et le titre. Les fonctions de repérage offrent des opérateur s pseudo-booléens ainsi que des expressions réguličres selon la terminologie de egrep (sous Unix).
L'utilisateur peut choisir le nombre maximum de résultats mais un seul format de sortie est disponible. Ce format, assez succinct, comprend le titre et l'URL d'un document dans lequel le lien repęché apparaît (citation).
Un site intéressant ŕ visiter pour ses références croisées mais dont la présentation des résultats est plutôt déficiente. Nous lui accordons deux étoiles (**).
Fonctionnant comme un catalogue, cet outil de recherche contient environ 400 guides, classés dans environ une douzaine de catégories, portant sur les ressources de l'Internet. La documentation (What's New) est plutôt succincte.
Les guides ont été rédigés principalement par des étudiants en bibliothéconomie et science de l'information de l'Université du Michigan. Ils sont écrits en HTML ou en format texte. Les utilisateurs sont encouragés ŕ proposer leur propre document. Ce tte base offre également un outil de recherche rudimentaire pour les guides écrits uniquement en format texte.
Un site intéressant pour les ressources de l'Internet mais qui n'utilise pas suffisamment les possibilités d'HTML et des liens hypertextuels. Nous lui accordons une seule étoile (*).
Répertoire
Cette base de données W3 est divisée en une douzaine de catégories et est maintenue par des éditeurs (guest editors). Comme dans l'exemple d'InfoSeek, on peut qualifier cette base d'hybride répertoire-index car il est possible d'utiliser une recherche par index. La documentation est complčte et excellente.
C'est un des rares outils de recherche de type répertoire qui permet des requętes complexes avec des opérateurs booléens. Les fonctions de troncature et de mots apparentés sont également disponibles. De plus, on peut spécifier une recherche sur des z ones tels le titre et les liens hypertextuels ou encore sur tout le texte. On peut également préciser la nature de l'objet recherché tels les titres de gopher, les ressources Telnet ou les pages de Galaxy.
L'utilisateur a le choix parmi trois formats de sortie. Le format de type long est trčs riche en information. En plus du titre, de la pondération et de la taille, ce format contient également un extrait du document, les mots les plus fréquents (avec leur occurrence), des en-tętes, la date du document et plus encore. Certainement un des sites qui présentent le mieux, avec Lycos, les résultats. De notre point de vue, c'est un des meilleurs outils de type répertoire. La diversité des services offerts est impressionnante et nous lui accordons quatre étoiles (****).
Répertoire et index
Une des particularités de ce catalogue est la possibilité de consulter également les bases de données Yahoo et WebCrawler ŕ partir d'une interface unique. The Whole Internet Catalog est constitué d'environ une douzaine de sujets, chacun divisé en d'au tres collections (il y a trois niveaux hiérarchiques). La méthode de l'éditeur est, lŕ aussi, également utilisée. Les utilisateurs sont encouragés ŕ soumettre leurs idées. La documentation est bonne.
Les liens (plus de 2,000) sont choisis dans les listes Hot List ou What's New. Il n'y a pas de fonctions de recherche. Il faut connaître, comme la plupart des bases de type répertoire, la nomenclature choisie. A chaque lien est as socié un compteur qui calcule le nombre d'accčs. Nous vous suggérons fortement cette base pour connaître les derničres nouveautés du Web et nous lui attribuons deux étoiles (**).
Répertoire
Cet outil de recherche épouse parfaitement la réalité de l'Internet. Il est complčtement distribué sur plusieurs sites. Plus de cinquante sujets sont maintenus indépendamment par différents collaborateurs qui font office d'éditeurs. Cette base est t rčs riche en information. Par contre, la documentation est déficiente.
Plusieurs classifications sont disponibles. Une d'entre elles ordonne les sujets tout simplement par ordre alphabétique. Il est également possible d'obtenir les sujets selon la classification LC (Library of Congress). Par contre, aucune fonction de recherche n'est offerte.
Cet outil est plus difficile ŕ utiliser comparativement ŕ Yahoo et Galaxy. Cet état de fait est probablement dű au manque d'homogénéité dans la présentation des pages produites par les différents collaborateurs. Néanmoins, un site fort intéressant et nous lui accordons deux étoiles (**).
Répertoire
Probablement l'outil de recherche de type répertoire le plus populaire dans le Web. Plus d'une vingtaine de catégories pouvant contenir jusqu'ŕ quatre niveaux hiérarchiques.
Des fonctions de recherche sont également disponibles de maničre ŕ spécifier le titre, l'URL ou la description d'un document. L'outil de recherche est assez rudimentaire (opérateurs pseudo-booléens, pseudo-opérateurs de proximité). La documentation e st trčs bonne et permet ŕ l'utilisateur de naviguer correctement dans le catalogue.
L'utilisateur peut en outre spécifier le nombre maximum de résultats. Il y a un seul format de présentation. Notons toutefois que les paramčtres de recherche sont mis en surbrillance dans les résultats. Un outil de recherche de type répertoire qui est certes intéressant. Nous lui attribuons trois étoiles (***).
Répertoire et index
Nous avons vu que les outils de recherche diffčrent dans leur type, leurs services de mise ŕ jour, de repérage et de présentation des résultats. La nature des objets répertoriés et l'information retenue dans les bases constituent les fondements du sys tčme d'information et ont un impact direct sur la qualité du repérage et les besoins de l'utilisateur. La qualité du repérage s'évalue en fonction des services offerts pour formuler nos requętes. Enfin, il faut que les résultats obtenus contiennent suff isamment d'information pour que l'utilisateur puisse en déterminer la pertinence.
On a vu également que des services, tels les opérateurs de comparaison et l'historique des recherches, sont absents dans les services de repérage des outils de recherche contrairement ŕ ce qui existe, en général, en informatique documentaire traditionn elle. Il sera intéressant d'observer l'évolution des services offerts par les outils de recherche ŕ cet effet.
Plusieurs critčres d'évaluation n'ont pas été abordés. Ceux-ci, croyons-nous, devraient faire l'objet de travaux futurs. Un élément fort important qui devra ętre étudié, ŕ notre avis, est la gestion des caractčres diacritiques dans les outils de rech erche. On connaît déjŕ les problčmes causés par une mauvaise gestion de ceux-ci en informatique documentaire.
Suite aux résultats obtenus de notre évaluation d'outils de recherche, nous avons quelques commentaires et suggestions ŕ émettre. Malgré sa faible évaluation, l'outil de recherche WebCrawler serait un bon point de départ pour le néophyte vu sa simplic ité d'utilisation. Pour exploiter la structure logique des documents, l'outil de recherche Open Text Index Web constitue, avec ses documents intégraux, un site trčs intéressant. Bien entendu, les classiques tels Lycos, Yahoo et InfoSeek sont ŕ visiter. En terminant, nous vous conseillons les outils de recherche Galaxy et Harvest Broker: de notre humble point de vue, elles se démarquent avantageusement des autres bases en termes fonctionnels.
Une derničre mise en garde: toute évaluation et comparaison d'outils de recherche, incluant l'étude présente, constitue une photo prise ŕ un moment bien précis. Contrairement au monde des logiciels de bureautique qui est beaucoup plus stable, l'évolut ion constante du Web rend ces comparaisons rapidement caduques. Par contre, les critčres établis au cours de cette étude sont ŕ notre avis beaucoup moins éphémčres.
Koster, Martijn. Robots in the Web: threat or treat? 1995. URL: http://web.nexor.co.uk/mak/doc/robots/robots.html.
Lanteigne, Diane. BLT-6451 Recherche documentaire automatisée 1: Présentation du travail individuel. École de bibliothéconomie et des sciences de l'information: 1995.
Leighton, H. Vernon. Performance of Four World Wide Web (WWW) Index Services: Infoseek, Lycos, WebCrawler and WWWWorm. 1995. URL: http://www.winona.msus.edu/services-f/library-f/webind.htm.
Liu, Jian. Understanding WWW Search Tools. Septembre 1995. URL: http://www.indiana.edu/~librcsd/search/.
Matrix of WWW Indices: A comparision of Internet indexing tools. 1995. URL: http://www.sils.umich.edu/~fprefect/matrix/.
Notess, Greg R. "Searching the World-Wide-Web: Lycos, WebCrawler and More." Online (1995): 48-53.
Paul, Kathryn, and Kathleen Matthews. Tools and Techniques for Searching the Web: Subject Trees and Search Engines. 1995. URL:http://burns.library.uvic.ca/KWM_Post_CLA.html.
Randal, Neil. "Search Engines: Powering Through the Internet." PC Computing (septembre 1995): 165-168.
Scales, B. Jane, and Elizabeth Caulfield Felt. "Diversity on the World Wide Web: Using Robots to Search the Web." Library Software Review 14, no. 3 (septembre 1995): 132-136.
Stanley, Tracey (ECLTSS@lucs-01 novell.leeds.ac.uk). Searching the World Wide Web with Lycos and InfoSeek. Computing Service, University of Leeds, UK: 24 octobre 1995. URL: http://www.leeds.ac.uk/ucs/docs/fur14/fur14.html.
Winship, Ian R. (ian.winship@unn.ac.uk). World Wide Web searching - an evaluation. Information Services Departement, Uniersity of Northumbria at Newcastle, UK, 1995. URL: http://www.bubl.bath.ac.uk/BUBL/IWinship.html.
Le taux de rappel se définit comme étant le nombre de documents pertinents sélectionnés divisé par le nombre de documents pertinents dans la base.
Le taux de précision se définit comme étant le nombre de documents pertinents sélectionnés divisé par le nombre de documents sélectionnés.
Le taux de bruit se définit comme étant la différence entre 1 et le taux de précision.
Le taux de silence se définit comme étant la différence entre 1 et le taux de rappel.
En général, ŕ quelques exceptions prčs tel Galaxy, ces index se limitent aux rubriques et sous-rubriques du plan de classification.
Sauf si le robot suit un protocole le soumettant ŕ certaines rčgles (voir les articles de Martijn Koster ŕ cet effet).
Cette norme est appelée Internet Anonymous FTP Archives (IAFA) for publishing information on the Internet with anonymous FTP.
La documentation n'est pas explicite sur la méthode utilisée pour calculer les mots les plus significatifs.
Quoique la documentation ne fournisse aucune explication concernant la définition d'une ligne (car il n'y a pas de notion de ligne en HTML)..
Le cas de Lycos est intéressant. Les chiffres, selon les études, varient de 3.6 ŕ 10 millions de documents.
Les formulaires HTML permettent de contrôler la saisie des données ŕ l'aide de cases ŕ cocher, de boutons de radios, de zones de saisie de texte, etc. Les outils de recherche qui n'utilisent pas de formulaires sont de plus en plus rares.
InfoSeek est l'exception. Pour les membres enregistrés ŕ InfoSeek, il est possible d'utiliser des comparaisons de dates. Malheureusement ce service n'est pas offert gratuitement.
Selon l'outil de recherche, un extrait peut correspondre soit aux premičres lignes du document, soit aux en-tętes du document, soit aux titres d'un menu gopher, etc.
WAIS: Wide Area Information Service.
Dans plusieurs études nous retrouvons cette caractéristique. Notons toutefois que celle-ci correspond tout simplement au principe d'adjacence.
Ce choix s'effectue dans l'interface de saisie de données (voir display option)..
Voir ŕ cet effet la bibliographie ci-jointe.
Les types d'objets sont classifiés de la maničre suivante: organisation, document, service, user, software, etc.
La proximité se définit ŕ l'intérieur de 100 mots.
Ceci étant dit, il faut quand męme prendre un certain recul sur les commentaires émis. Lycos, tout comme InfoSeek, est ŕ but lucratif.